

The Need for Autonomy: Why GRC Can’t Rely on Coordination Anymore


In growing organizations, GRC teams are being asked to move at the speed of growth and revenue, without increasing risk. That tension is forcing a shift in how GRC functions are designed.
The operating model that once worked may feel outdated as you pursue new territories and bigger logos. However, a shift is imminent.
Previously, your GRC function could run on effort because you knew where evidence lived and knew which engineer to call if some evidence was missing or outdated. Risk reviews were manageable, and requests to prove posture were far less frequent.
However, geographical expansion and new relationships invite greater scrutiny. The number of controls grows. Board visibility increases. Regulatory overlap expands. Sales cycles become more GRC-intensive. But you cannot badger Engineering teams for evidence artifacts all the time.
If this sounds familiar, this blog can help you start thinking about how to shift your operating model to meet new realities. We’re not talking tooling here; we’re looking at mindset.
The hidden cost of coordination

Most GRC functions are coordination-heavy by design.
This isn’t intentional. It is a consequence of scaling up. Coordination becomes the silent overhead that slowly creeps into processes, slowing things down before you get a chance to address it.
The traditional operating model assumes that coordination scales with the organization’s growth. But instead, you accumulate what can be called coordination debt, a hidden operational cost created when too many processes depend on manual follow-ups, cross-team nudges, and tribal knowledge. Like technical debt, it compounds quietly. You don’t feel it every day. You feel it when velocity slows, when escalations increase, or when one person leaving creates disruption.
It most often plays out like this: Security questionnaires trigger cross-functional threads. Risk reviews depend on meetings. Evidence collection requires follow-ups. Control validation happens on schedules. Audit workload intensifies seasonally.
| Coordination debt is a hidden operational cost created when too many processes depend on manual follow-ups, cross-team nudges, and tribal knowledge. |
The concept of autonomy
Before we discuss autonomy through the GRC lens, let’s talk about what it means in general. The Merriam-Webster dictionary defines autonomy as a state of being independent, free, and self-directing.

The concept of autonomy was applied to the tech world, not in the 2020s, vis-à-vis AI, as many would expect. It actually came up in 2001, over two decades ago, when IBM introduced the concept of autonomic computing. The term referred to systems that could manage themselves with minimal human intervention. When IBM pioneered the concept, it envisioned an autonomic system with 5 key qualities: self-configuring, self-healing/self-repairing, self-tuning/self-optimizing, self-defending/ self-protecting, and self-aware/context-aware.
Interestingly, the problem statements IBM was trying to solve at the time closely mirror the ones organizations face today. In 2001, IBM faced increasingly complex IT environments, not to mention accelerated device growth byalmost 40% per year. Moreover, throwing more people at the problem wasn’t an option because labor costs were already high, and the complexity increased the risk of human error.
How does the concept of autonomy translate to GRC?
Autonomy in a GRC function means bringing IBM’s 5 principles of autonomic computing into GRC workflows.

In an autonomous GRC function, you will see the following traits:
1. Controls validate continuously
Controls are not static artifacts. They are reflections of dynamic systems.
When validation is periodic, drift accumulates, and misconfigurations go unnoticed. But a control that fails in week one and is discovered in week twelve creates exposure across that entire window. That’s no way to earn customers’ trust. They don’t differentiate between “temporary drift” and “systemic weakness.” They simply view that approach as high risk. Autonomy here means that red-flagging happens as systems change.
The benefits include a far-reduced exposure window, fewer late-stage surprises during audits and deals, and greater confidence in the current state of controls.
You can see the self-awareness principle of autonomy at play here.
2. Ownership is embedded, not chased
In coordination-heavy models, GRC tracks, reminds, and escalates. But ownership that depends on reminders is not scalable when control owners multiply, and follow-ups consume GRC bandwidth.
On the other hand, if ownership is embedded into workflows, control responsibilities are built into how teams already operate, instead of being tracked through follow-ups and reminders.
GRC teams get to perform more valuable duties than chasing.
Did you notice the self-governing and self-remediating principles of autonomy at play here?
3. Revenue-linked trust requests don’t trigger fire drills
The road to deal closures is paved with security reviews. But if every deal requires a patchwork of evidence assembly, several architecture clarifications, and a bunch of cross-team escalations, deal velocity will take a hit.
(And, in general, that’s not a very trustworthy look as far as potential customers are concerned.)
Autonomy here means your sales team can address those security reviews without intervention. That means a library of standardized, reusable responses,
pre-validated architecture positions and current control evidence.
This is another area where the self-awareness principle of autonomy comes into play.
4. Risk surfaces without waiting for a quarterly review
In coordination-heavy models, escalation often depends on review cycles. Risks are discussed in meetings. Exceptions are evaluated at checkpoints. Control failures are examined during audits.
That works until something changes between those checkpoints.
In an autonomous system, control failures are immediately visible, and exceptions trigger alerts, enabling instant escalation and timely action.
You can clearly see autonomous principles like self-awareness, self-healing, and self-defending at play here.
5. Institutional knowledge is systematized
As GRC functions grow, context naturally centers on experienced team members. But if control rationale lives in memory, historical responses live in inboxes, and exceptions are explained verbally, continuity depends on availability.
Autonomy calls for structured evidence repositories and a searchable library of prior questionnaire responses, control rationale, and exception justifications. It eliminates instability amidst growth, attrition, and restructuring.
The self-awareness principle of autonomy comes up here again.
A sidenote: As we explore the concept of autonomy for GRC teams, it’s important to make a key distinction: autonomy is not automation. Autonomy is also not AI. Automation completes tasks. AI accelerates analysis and reduces manual effort.
Automation and AI are potential tools or components. Autonomy is the outcome. The intended state. Automation can gather evidence. AI can draft responses or detect anomalies. Neither is the point here.
The point is that autonomy allows your GRC function to no longer rely on constant coordination to remain effective. You function independently and efficiently with greater agility.
| Autonomy is not automation. Autonomy is also not AI. Autonomy is functioning independently and efficiently, with agility. |
How do you know it is time to evolve into an autonomous system
The short answer is, you’ll feel the need operationally. (In fact, there’s a high chance you’re already feeling it even if you haven’t named it) Here are some reasons why you need autonomy and where the need for it will show up:
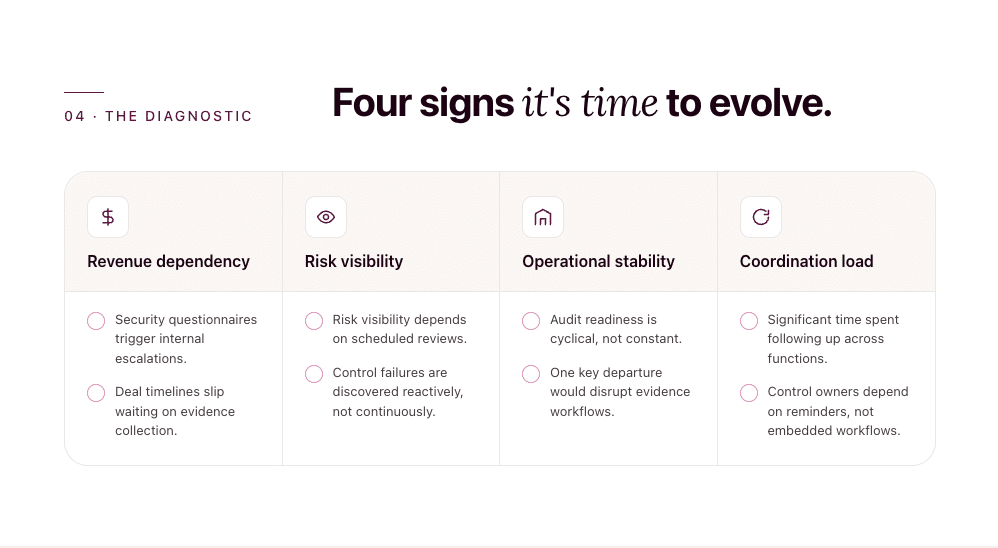
1. When trust operations become a revenue bottleneck
Do you remember when your sales team pinged you about a deal that was “almost closed”, except they needed a completed 200-question security questionnaire in 48 hours? And this landed right in the middle of an ongoing audit. Engineering was already stretched. So you ended up drowning in evidence collection, architecture explanations, and internal follow-ups, knowing that a delayed response could stall revenue.
Here’s why this happens:
In a coordination-heavy model, you orchestrate people. You pull in engineering, your team searches for the latest evidence. You reconcile inconsistencies.
In an autonomous model, you orchestrate systems. You set things up such that control evidence is current, responses are standardized, architectural positions are pre-validated, and evidence is not assembled from scratch for every deal.
The shift is subtle but meaningful: From reactive coordination to system-enabled efficiency.
2. When risk visibility breaks under velocity
Have you ever wrapped up a quarterly risk review knowing it accurately reflected the state of controls at that moment, while also knowing that systems, access, and vendor integrations would inevitably change the very next moment? Or experienced a control gap surfacing during audit preparation, not because it was ignored, but because it drifted quietly between review cycles?
Here’s the problem: Calendar-based assurance works until risk moves faster than your manual updating and reporting cycle.
Autonomy shifts you toward real-time assurance, but without increasing team size or dramatically multiplying budgets. You want to get to a state where:
- Control evidence updates when source systems change, not when someone requests it.
- Ownership is tied to operational systems, not maintained in parallel spreadsheets.
- Exceptions surface at the point of drift, not during the next audit cycle.
- Risk visibility reflects the current state, not last month’s review.
- And overall, you spend less time gathering status and more time strengthening your GRC posture.
3. When concentrated expertise creates continuity risk
The need for autonomy also becomes visible in how knowledge accumulates inside a growing GRC function.
Consider a situation in which a senior GRC lead was on leave and a customer asked for clarification on a legacy control exception. The documentation existed—somewhere—but the context behind the decision lived mostly in conversations and experience.
Honestly, this is just how many high-functioning teams operate under pressure.
However, as complexity increases and the pace of business accelerates, reliance on individual context becomes harder to sustain. Teams grow. Roles evolve. People move on. New hires join mid-cycle.
If critical control rationale or evidence history lives primarily in experience rather than in systems, continuity depends on the availability of those with experience. Your GRC function cannot afford to slow down because a specific team member is unavailable (and being human, that’s bound to happen).
Autonomy ensures continuity, even as teams evolve, because it reduces that dependency by institutionalizing expertise.
The shift at hand
For GRC heads at fast-growing organizations, expectations are evolving from maintaining controls to ensuring they hold strong as you scale.
The coordination-heavy model that carried you through earlier growth phases was not wrong when it worked. It simply wasn’t designed for the compounding complexity you face today. At scale, you cannot strengthen your GRC function by adding more manual coordination. Each additional dependency on follow-ups and individual effort increases the likelihood of gaps.
Autonomy is not a luxury at enterprise scale. It is structural stability.
And increasingly, it is a necessity.
Author
Raynah
Raynah is a content strategist at Sprinto, where she crafts stories that simplify compliance for modern businesses. Over the past two years, she’s worked across formats and functions to make security and compliance feel a little less complicated and a little more business-aligned.Go beyond the surface and uncover the governance, risk, and compliance insights that actually matter.


Win digital goodies for boardroom success


Explore more








research & insights curated to help you earn a seat at the table.

