

5 AI Governance Strategies That Don’t Block Teams: The Practitioner Playbook

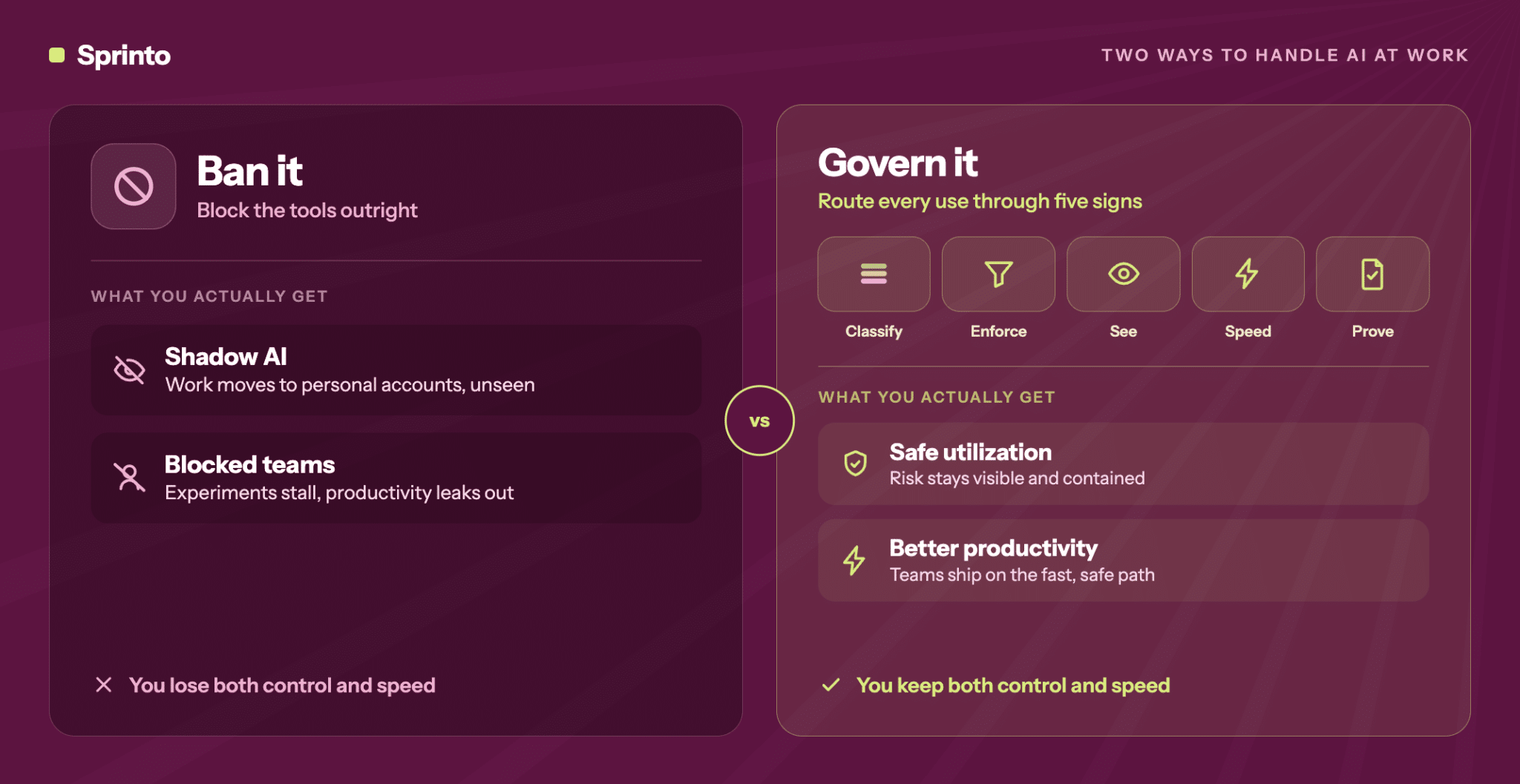
– AI governance fails when it’s too loose to catch anything or too tight to let teams move
– The answer is making the safe path faster than the workaround, not blocking the workaround
– Classify by data type and destination, enforce at the point of exposure, log everything
Imagine data leaving the environment through unvetted tools because nobody told the sales team their AI notetaker wasn’t on the approved list. Or AI-generated code reaching production without review because the engineering team assumed the model had already checked it. We bet these are nightmares you would hate to see coming alive.
The challenge is that most AI governance responses create a different kind of damage: teams slowed down, experiments killed before they start, productivity gains handed to competitors while your organization runs an 8-week approval cycle for a two-hour experiment.
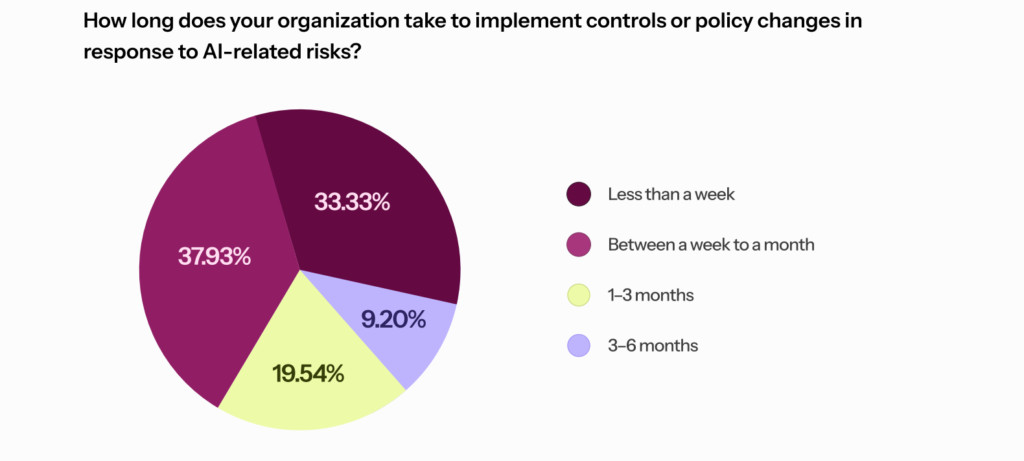
Our State of AI in Risk 2026 report found that 2 in 3 organizations take between 1 week and 6 months to implement controls or policy changes in response to AI-related risks. But when it takes too long to implement controls or policy updates for AI-related risks, GRC teams end up either stalling promising tools or witnessing employees use them in the shadows anyway. And, both outcomes increase risk.
The question practitioners are actually working through is: how do you hold the line on real risk without becoming a blocker to the business? The question is everywhere; look at these Reddit threads, for instance:

In this blog, we have rounded up the best Reddit practitioner recommendations on how to implement AI governance so that it serves as an enabler rather than a blocker.
Blog in a nutshell
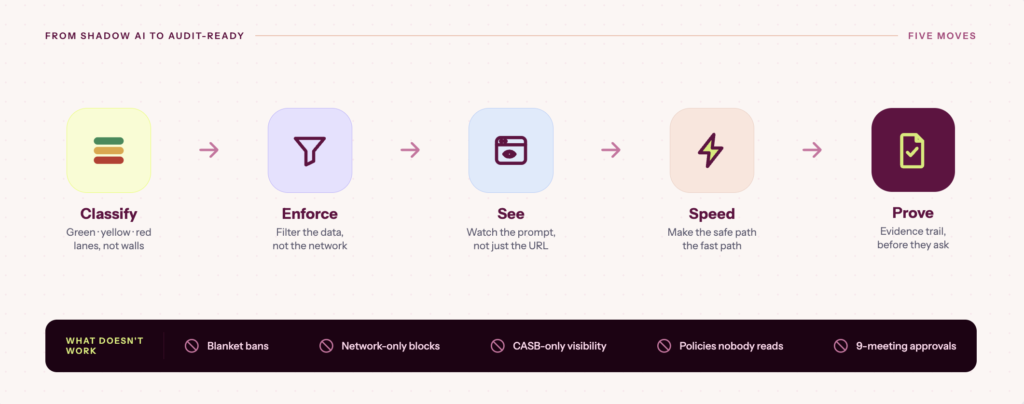
1. Replace the allow/block binary with a three-lane model (green/yellow/red)
One good idea for an easily deployable framework came from a practitioner on r/devsecops who had been through cloud security’s growing pains and recognized the same pattern repeating itself. Their argument: stop treating AI as categorically different from other infrastructure risks, and start classifying actual risk paths.
One of the most structured responses in the thread came from a commenter representing a vendor in the AI data security space, in r/devsecops’ thread How are people handling AI data security without blocking every internal AI experiment?, “What worked for us was a 3-lane model. Green lane: public or low-sensitivity data, approved SaaS copilots, normal logging. Yellow lane: internal data with contracts, retention limits, no training on prompts, DLP on ingress and egress, and human review before production use. Red lane: regulated data, customer secrets, prod dumps, source tied to auth flows—only isolated internal models or no AI at all.” Vendor perspective or not, the logic holds, and it maps directly onto how mature security teams approached cloud risk a decade ago and EU AI Act requirements today.
A separate commenter, u/Heavy-Foundation6154 on the same thread added, “An internal chatbot whose chats aren’t used as training data is a different level of risk than an external agent that has access to internal databases.” The destination matters as much as the data type.
Together, these two comments describe a framework that pre-answers the decision so non-technical employees never have to make a judgment call that’s beyond their understanding.
The lanes are set by the GRC or security team upfront within a classification matrix that maps data types to approved AI destinations, and are maintained the same way you’d maintain a data inventory. Teams access the matrix and take actions accordingly.
For example: A marketing team using AI to draft blog content checks the matrix, sees it’s green, and picks from the approved tool list; the content was going public anyway. A sales team using AI to summarize call notes before a proposal checks the matrix, sees it’s yellow, and knows they need an enterprise-licensed tool with a DPA in place before they proceed; deal terms and customer context aren’t regulated, but they’re not public either. A healthtech analyst considering running patient records through any external model checks the matrix, sees red, and knows the answer is no.
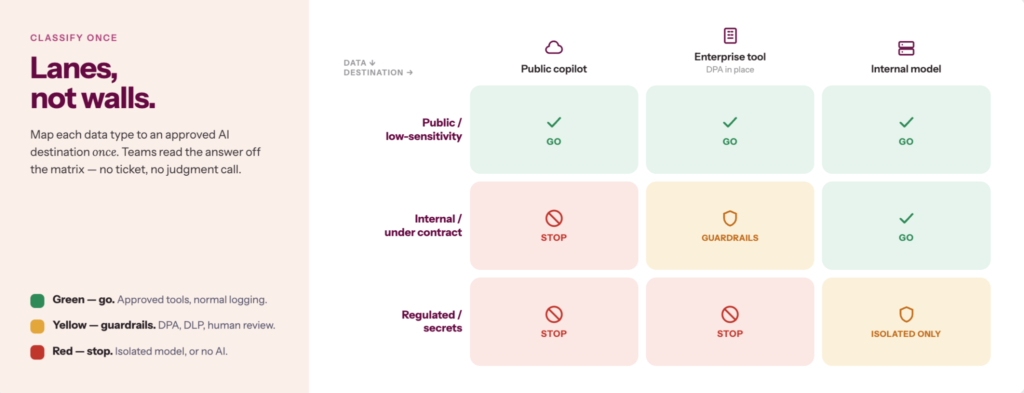
This model also maps onto established frameworks without needing to be rebuilt for each one.
- NIST AI RMF’s Govern and Map functions follow the same logic, i.e., classify the use case, assign the risk tier, and apply the controls.
- The EU AI Act is more specific: its own risk tiering maps almost directly onto the three lanes, with High-risk AI use cases such as credit scoring, hiring, medical devices, and critical infrastructure landing in Red by regulation, not just by internal policy. For organizations operating in the EU, the three-lane model isn’t only internal governance hygiene. It’s also how you identify which uses trigger mandatory compliance obligations under law.
1. Build a classification matrix: rows are data types, columns are AI destinations (public model, enterprise-licensed tool, internal model). Each cell gets a Green / Yellow / Red rating
2. Define the Yellow lane controls explicitly: which tools are approved, DPA required, no training on prompts, and human review before production use
3. Publish the matrix where teams can self-serve. It only works if people can find it without raising a ticket
2. Enforce at the data layer, not the network perimeter
If your first instinct when AI risk surfaces is to block at the firewall, you’re not alone, and you’re not wrong to tread carefully. But the firewall is the wrong place to enforce AI governance, and here’s why it doesn’t hold.
As u/Cautious_Map25 put it on r/devsecops’ thread How are people handling AI data security without blocking every internal AI experiment?, “Most teams that are doing this well aren’t banning AI, they’re shifting to a controlled enablement model instead. They focus on real-time visibility into what data is being used in prompts and AI workflows, plus lightweight policies that guide rather than stop usage.”
The thread also got specific about where that control actually needs to sit. As u/Master_Baby_2700 put it: “What seems to work better is treating AI like any other data access layer: classify sensitive data, monitor what AI apps/connectors can reach, and put guardrails around high-risk datasets instead of blocking everything globally.” Personal accounts, mobile browsers, and home networks don’t route through your corporate proxy. Network-layer controls were built for a different threat model.
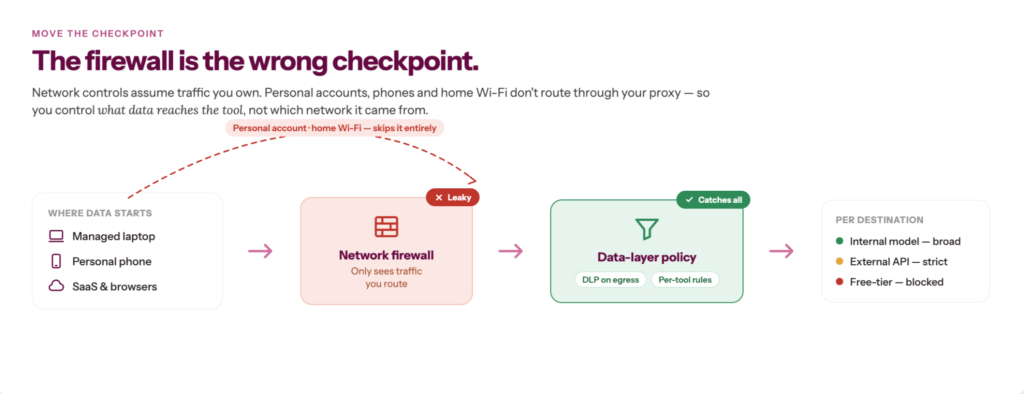
The risk of sending data to an internally hosted model is structurally different from sending it to a free-tier consumer product. Treating them identically produces governance that’s simultaneously too tight in some places and too loose in others.
1. Define data types that are never permitted to reach external AI APIs — regulated data, source code, M&A, or board-level information — and enforce this at the integration layer, not the firewall
2. Configure per-tool policies: internal models get broader access, enterprise-licensed external tools get defined data-type permissions, free-tier tools get blocked for anything above green
3. Apply DLP rules at the point of egress to external APIs — flag or block classified data before it leaves, not after
3. Close the gap that CASB was never built for
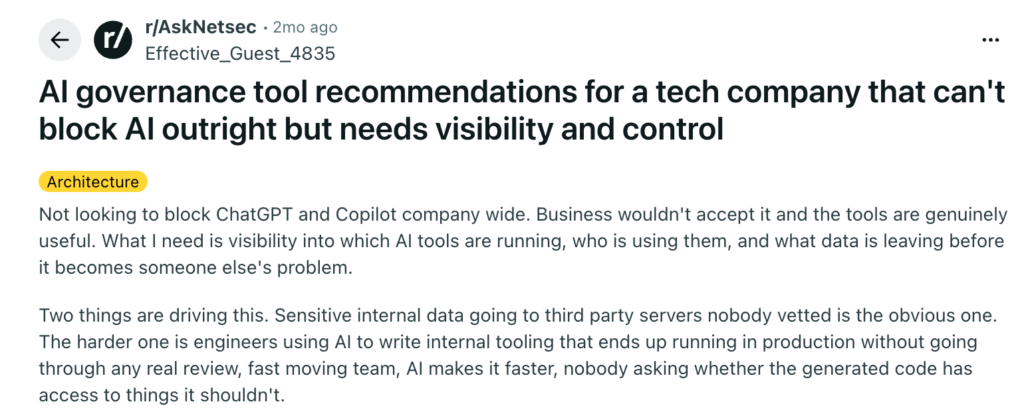
The Cloud Access Security Broker gap was articulated by was articulated by u/Effective_Guest_4835, a security professional posting on r/AskNetsec’s thread, AI governance tool recommendations for a tech company that can’t block AI outright but needs visibility and control, who was running security for a fast-moving tech company and had already exhausted the standard toolkit. In their words, “Browser-based AI usage in personal accounts goes through HTTPS sessions that most inline controls see nothing meaningful in. That gap between what CASB catches and what’s actually happening in a browser tab is where most of the real exposure is.”
Your CASB sees that someone visited claude.ai. It sees nothing about what they pasted into it. What if they pasted an unexecuted contract, a customer or patient record, a credit model, or proprietary source code?
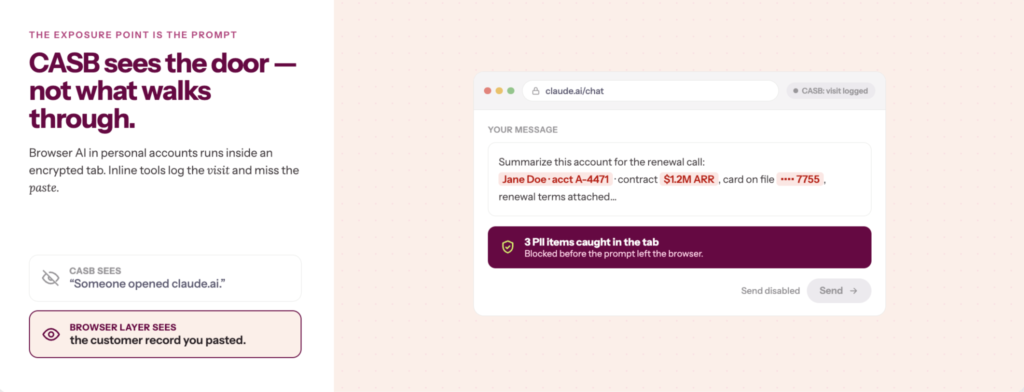
CASB was designed for SaaS visibility, not for what’s happening inside an encrypted browser session. The practitioners responding to this thread were recommending browser-layer controls that sit inside the tab, seeing what’s typed, copied, and uploaded before it leaves. It can flag a PII paste, block an upload to a free-tier tool, or warn the user before they hit send. The exposure point is the prompt, and that’s where these controls sit.
1. Audit your current shadow AI exposure: assume your CASB data significantly underestimates actual AI tool usage. Remember: browser-based and mobile usage won’t appear
2. Evaluate browser-layer controls as a complement to your existing CASB, not a replacement.
3. They address different parts of the problemAt minimum, configure DLP policies to detect sensitive data being uploaded to known AI domains, even if full browser-layer controls aren’t yet in place
4. Make the safe path genuinely faster than the workaround
This is the design principle that holds everything else together, and it was stated simply by u/BasilThis2161 in a thread How are people handling AI data security without blocking every internal AI experiment?. They say, “We found that giving devs a specific ‘safe’ environment with an enterprise agreement was the only way to actually keep visibility on what was happening.”
Governance is an experience problem as much as a policy problem. If using an approved enterprise tool is faster and less friction than a personal account, people will use the approved tool, and you keep visibility. If the approved path requires a committee review and a six-week wait for a two-hour experiment, people will use their phones, and you’ll have neither compliance nor visibility. The mechanism by which governance actually works at scale is making the safe choice the easy choice.
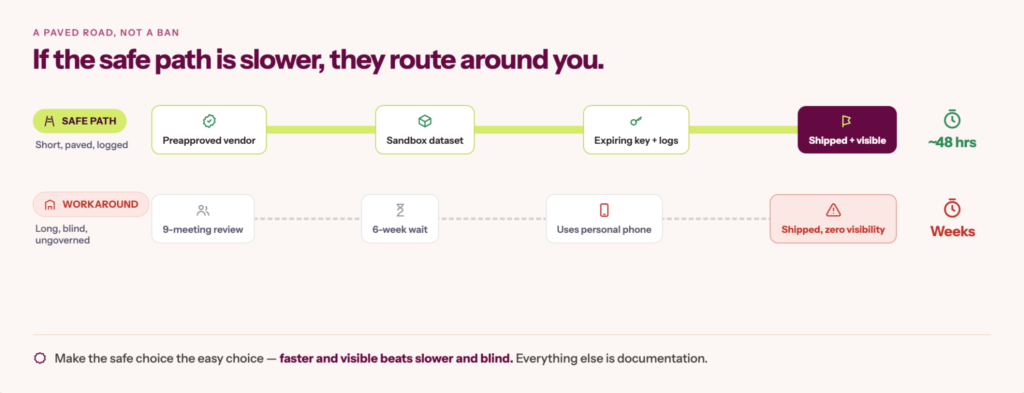
That said, making the safe path the quickest path may not always be possible.
That is when one-on-one conversations and empathy matter. Show up as supportive, not obstructive. You might want to try something along the lines of, “I see why this is useful. I want to help you get there. I just need to make sure we are not exposing customer data, granting risky permissions, or creating something we cannot monitor. Let’s find the fastest safe route.” Helping the team understand the risks, implications, and possibly dire consequences often goes a long way.
On occasion, a tool may still be a no-go. In those cases, the goal is not to shut down the request. It is to understand what the team was trying to do and find a safer path: a preapproved vendor, narrower permissions, sandboxed data, a temporary key, or a different workflow.
1. Build a pre-approved AI vendor list with DPAs already in place. Teams pick from it, they don’t start from scratch
2. Create a fast-track intake process for new AI use-case requests: define a 48-hour turnaround for Green and Yellow classifications, escalation only for Red
3. Provide sandbox environments with pre-approved, non-sensitive datasets so teams can experiment without touching production data or waiting for a security review
5. Build the audit trail before anyone asks for it
Many GRC teams might already have logging infrastructure, SIEM pipelines, and audit processes in place, but are still building the AI-specific layer on top of them. The problem isn’t that teams don’t know they need evidence, or even that they arent’ trying hard to gather it. It’s that when the auditor, the acquirer, or the prospect’s security team actually asks, the evidence is scattered across four systems and nobody owns the record because as u/jcarmona86 put it on r/AI_Governance’s thread Where does AI approval evidence actually live in your org?, “Most orgs approved AI tools reactively, tool by tool, with no defined evidence standard. You end up with a bunch of artifacts instead of a governed record. Someone’s inbox has the original approval email. A SharePoint folder has the vendor questionnaire. A Confluence page has the meeting notes. The actual risk assessment is a Google Doc that three people edited and nobody owns. Each one tells part of the story. None of them are the record.“
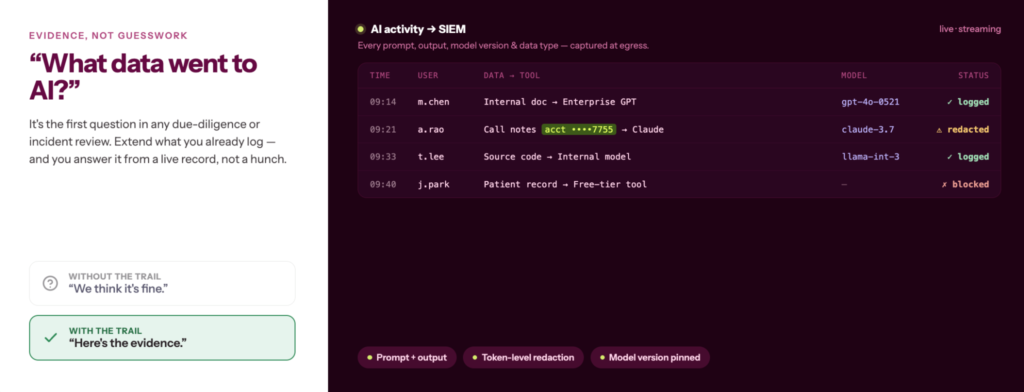
The approval record is only the starting point. For AI, that means extending what you already log: logging prompt inputs and outputs to SIEM, token-level redaction of email addresses and account IDs before they reach external APIs, and a record of which model version was in use at the time. Model versions matter because the same prompt can produce materially different outputs across versions, and when a prospect’s security team or a regulator asks, that record is what drives trust.
1. Extend your existing logging infrastructure to capture AI-specific signals: which tool, which data type, which user, which model version, at what time
2. Apply token-level redaction for PII and account IDs before prompts reach external APIs — protect what leaves even when you can’t prevent it from being sent
Build an AI use-case register: a live record of approved AI workflows, the tools used, and the data types involved — this is the document that answers the due diligence question
Two gaps these AI governance best practice threads don’t close
Everything above applies to AI, as most organizations currently use it: people make requests, and AI returns responses. However, two patterns are already breaking that model, and the practitioners’ threads are honest about still thinking through how to govern these use cases.
- AI-generated code reaching production.
u/Effective_Guest_4835, posting on r/AskNetsec’s thread AI governance tool recommendations for a tech company that can’t block AI outright but needs visibility and control, flagged an increasingly common scenario: Engineers using AI to write internal tooling that ends up running in production without going through any real review—fast-moving team, AI makes it faster, nobody asking whether the generated code has access to things it shouldn’t.” Speed of generation is not the same as readiness for production. The code review process that applies to human-written code applies equally here—in some respects, more so, because the volume is higher and the developer may have limited visibility into what the model actually produced.
- Agentic AI
This is the harder problem. As u/Unfair-Plum2516 put it in the same thread: “A lot of current ‘governance’ is really just observability after the fact. The harder question is: can the system recognize risky behavior before the action executes? Because once agents have access to production systems, logs alone are not enough. At that point, you need real execution boundaries, approval logic, and policy enforcement inside the workflow itself.”
Every framework described above was designed for a world where AI responds to prompts. Agentic systems that autonomously execute actions, chain API calls, send communications, and modify records need a different layer: execution boundaries, pre-action approval logic, and policy enforcement inside the workflow rather than around it. The people in these threads are working on it. Nobody has fully solved it yet.
Strategies that could help:
- Extend your existing code review policy to cover AI-generated code explicitly. Make it a named requirement, not an assumption
- For agentic systems already in use or under evaluation, map every system action to a human approval checkpoint before it’s permitted in production
- Treat agentic AI as a new risk category in your risk register. Document what actions each agent can take, what data it can access, and what the rollback procedure is
How Sprinto helps you operationalize these AI governance best practices
Turning all the actionables above into workflows, controls, and audit-ready evidence without building everything from scratch might seem daunting, but Sprinto can help.
1. Build your classification matrix in Sprinto’s risk register
Define your Green/Yellow/Red lanes as controls, map them to your AI Acceptable Use Policy, and use custom AI Actions in AI Playground to create a no-code intake workflow. When a team submits an AI use-case request, the action classifies it by data sensitivity, AI destination, vendor type, and whether regulated data is involved, and returns a lane classification with required controls. No engineering required.
2. Run AI vendor due diligence before teams adopt tools
Sprinto’s Vendor AI Due Diligence workflow surfaces the questions that matter: does the vendor train on customer prompts? Is there a DPA? Are logs exportable? Is enterprise SSO supported? Is regulated data permitted? Sprinto AI accelerates the review process by generating findings from vendor security documents, so your team doesn’t have to read SOC 2 reports manually.
3. Map your AI policy to controls and evidence
Turn your AI Acceptable Use Policy into an internal document in Sprinto, map it to controls, and link those controls to checks. Sprinto AI handles the policy-to-control mapping, so the governance work you’ve done becomes audit-ready evidence rather than a document that sits in a folder.
4. Close evidence gaps before they become audit findings
Sprinto’s Evidence Gap Analysis flags missing, outdated, or irrelevant evidence during uploads. For AI governance specifically, that means tracking: approved tool list, vendor DPAs, AI use-case register, risk assessments, human review records for AI-generated code, and attestations for restricted data handling. When a customer security review or regulatory inquiry arrives, you’re pulling from a live evidence set, not scrambling to reconstruct one.
Takeaway
AI governance fails in one of two ways: it’s so loose that risk is invisible, or so tight that teams route around it and risk becomes invisible anyway. The organizations getting this right aren’t choosing between control and speed—they’re building governance that makes the safe path the fast path. That means data mapped before policy is written, lanes that answer the question before it gets asked, enforcement at the point of exposure rather than the network edge, and an evidence trail that holds up when someone external comes asking. None of these AI governance best practices requires starting from scratch. It requires taking what your GRC program already does well and extending it deliberately into AI.
Last but not least, here are a few more resources to help you plan and perfect your AI governance:
- Find out how your peers are faring with AI governance
- Get a roadmap for AI governance based on how other CISOs and GRC heads handle AI governance
- Evaluate your AI governance maturity
FAQs
No. A policy defines what’s permitted. It has no enforcement mechanism, no audit trail, and no way to detect when it’s being ignored. If an employee pastes customer data into a free-tier AI tool today, a policy says they shouldn’t have. Governance means you’d know they did, with evidence of what data was involved and where it went. For MM and ENT organizations, the policy needs to be backed by controls, mapped to evidence, and auditable on demand.
AI security asks whether AI systems can be compromised via prompt injection, model manipulation, or infrastructure vulnerabilities. AI governance asks whether AI is being used responsibly, on the right data, with the right documentation, and with accountability when something goes wrong. Security protects the system. Governance protects the organization. Both matter, and neither covers the other’s ground, which is why they need separate ownership.
The three-lane model is framework-agnostic. It’s a risk classification approach, not a compliance checklist. In practice, it maps cleanly onto SOC 2 (vendor management, access controls, logical access), ISO 27001 (information classification, supplier relationships), GDPR and DPDP (data processing agreements, purpose limitation), and HIPAA (BAAs required for any PHI, no exceptions at Red). Build the matrix first, then map each lane’s controls to the applicable frameworks. You’ll find significant overlap, so the work does 2x-3x the lift rather than multiplying.
The risk isn’t the assistant, but rather, the output. AI-generated code can contain subtle vulnerabilities, inappropriate access permissions, or IP-encumbered patterns that pass a casual review precisely because it looks finished. Treat the code the same way you’d treat any sensitive data: enterprise-licensed tools only for proprietary codebases, and no free-tier tools with unclear data retention policies. Most importantly, AI-generated code must go through the same review process as human-written code.
When an agent hands back finished work, such as a sent communication, a modified record, an executed transaction, or ready code, the output is complete by definition. What you can’t see is which assumptions it made or which steps it oversimplified. Governing the output isn’t enough; you need visibility into the process. That means hard-scope limits on what each agent can do, human approval before any irreversible action, and a full action log that captures not just what the agent did, but what triggered it and which model version was running.
Author
Raynah
Raynah is a content strategist at Sprinto, where she crafts stories that simplify compliance for modern businesses. Over the past two years, she’s worked across formats and functions to make security and compliance feel a little less complicated and a little more business-aligned.Go beyond the surface and uncover the governance, risk, and compliance insights that actually matter.


Win digital goodies for boardroom success


Explore more








research & insights curated to help you earn a seat at the table.

