

How to rethink TPRM architecture for agentic, runtime, and AI dependency risks


TPRM has always been about understanding who your key vendors are, what access they hold, and safeguarding your business against the breaches, downtime, and disruption that could follow if they fail. A vendor-side diligence model built for a world where third-party risk was largely static. In an AI third-party risk age, that model is no longer sufficient. Three things have changed:
AI is expanding the third-party risk surface, creating a zero-day exploit environment, and making vendor concentration harder to see. Most TPRM programs were not architected for any of the three
Traditional TPRM architecture misses stacked dependencies, regulatory access shock, and exit drag — the risks that don’t show up in a questionnaire
Runtime monitoring needs become part of TPRM architecture to catch mismatched actions, data re-routing, and suspicious memory writes
Change # 1: AI integration is expanding the risk surface beyond AI-native vendors.
Productivity platforms, HR systems, finance tools, and cybersecurity products are all inheriting runtime risk through the AI layers embedded in them. The governed surface has grown quietly, without most programs recalibrating to match.
Here’s a scatter chart that demonstrates this shift visually:
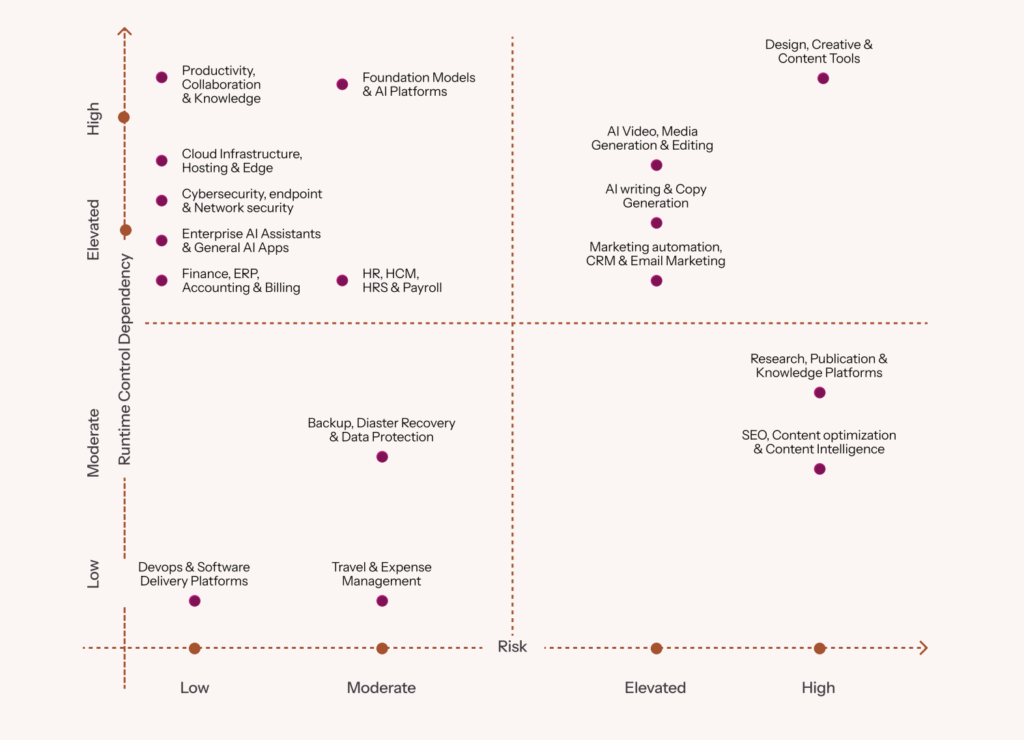
Source: Vendor Category Landscape, 2026
Notice that the majority of popularly used tools show elevated to high runtime risk, needing runtime controls to ensure they’re working as intended.
Change # 2: AI has introduced a zero-day exploit environment that TPRM architecture was never built for
When a model becomes capable of discovering vulnerabilities in legacy banking systems or critical infrastructure at scale, the capability itself becomes a systemic risk event, regardless of who owns it, who governs it, or what your contracts say. Anthropic’s Mythos models and similar frontier capabilities being developed across labs illustrate exactly this, and governments are already responding with export controls, access restrictions, and national security orders moving faster than any vendor contract could have anticipated. The risk is not just what your vendors do with AI. It is what AI makes possible in the wrong hands, and whether your program can demonstrate it is governing for that risk.
Change #3: AI Vendor concentration risk is increasing and becoming harder to detect.
Several “different” tools in your stack may sit on the same underlying model provider, cloud region, or API layer. When that shared layer is disrupted by deprecation, a regulatory decision, or a government order, the blast radius isn’t limited to one vendor. It’s every workflow stacked on top of it. The developing Mythos story bears a classic example of this, too. When Anthropic abruptly disabled its Fable 5 and Mythos 5 models after a US government order citing national security concerns, in June 2026, any enterprise that had built critical workflows on those capabilities lost access overnight. The vendor was fine. The product worked. But access was gone nevertheless.
This blog covers what modern TPRM needs to account for to respond to these three changes:
🛡️Three dependency risks you need to map before your next renewal cycle, and
🛡️Three runtime signals your monitoring should already be watching for.
| Risk | TPRM Field | Owner | Evidence |
| Stacked dependency | Fourth-party mapping; dependency chain documentation | GRC / Security | Vendor dependency map showing underlying model providers, cloud regions, and API layers; updated at each renewal |
| Regulatory access shock | Regulatory exposure register; geographic and jurisdictional access flags | GRC / Legal | Documented assessment of regulatory access risk by vendor, region, and use case; reviewed when geopolitical or regulatory changes occur |
| Exit drag | Exit feasibility assessment; vendor lock-in scoring | GRC / Procurement | Exit assessment completed at each renewal; documents switching cost, workflow dependency, and recovery timeline |
| Mismatched actions | AI agent action logs; task scope monitoring | Security | Logged action trails mapped to originating user requests; flagged exceptions with resolution records |
| Data re-routing | Output inspection logs; DLP monitoring for AI-generated content | Security / GRC | Evidence that AI outputs are inspected at the channel level, not just at storage; flagged anomalies with documented review |
| Suspicious memory writes | Memory audit logs; write monitoring after untrusted content ingestion | Security | Timestamped memory write logs; evidence of review after agent processes untrusted material; flagged changes with documented disposition |
What AI vendor dependency risks should your TPRM architecture mitigate?
- Stacked dependency
A vendor is rarely just one dependency anymore. Your vendor may sit on a model provider, cloud region, vector database, payment rail, identity layer, or API provider you never directly assessed. The AI dependency risk is that several tools you treat as separate dependencies (some even purchased as intentional redundancy or backup) may actually share the same underlying layer or foundation model, one you don’t know about and don’t control. If three business-critical workflows all route through the same model provider, your concentration risk is not spread across three vendors. It is stacked beneath them. And if that layer changes, gets throttled, deprecated, or switched off, the workflow breaks regardless of what your contract says.
map the full AI supply chain dependency, not just the vendor name on the contract, and not just the application in front of the capability.
- Regulatory access shock
AI-based third-party failures can begin with a rule change, an export-control directive, a sanctions decision, a data-transfer restriction, or a government order. The vendor may still be secure. The product may still work. But access may no longer be available to the same users, regions, use cases, or data flows.
In mid-June, Anthropic abruptly disabled its Fable 5 and Mythos 5 models after a US government order citing national security concerns. Any enterprise that had built critical workflows on those capabilities lost access overnight, with no contractual recourse and no warning. The vendor was fine. The product worked. The access was simply gone.
capture where vendor access depends on geography, nationality, data location, or regulatory regime.
- Exit drag
A relationship becomes harder to govern when vendor lock-in leaving becomes unrealistic. The risk builds through integrations, workflows, data formats, prompts, and user habits. By the time the relationship becomes uncomfortable, switching may mean redesigning the process, not just replacing the tool. If a risk-scoring workflow is built around one vendor’s logic, fields, and automations, exit goes from a procurement task to an operating change. And that can disrupt the very workflows you built the vendor relationship to support, take quarters to stabilize, and end up costing far more in operational disruption than anyone budgeted for.
assess vendor exit risk and feasibility before onboarding and every renewal, not after the relationship is already too embedded.
What AI vendor runtime risks should TPRM architecture be tracking?
- Mismatched actions
Sure, agentic AI and AI-enabled systems are non-deterministic, but any chain of actions should make sense relative to a given task. For example, a compromised agent may still appear to be doing normal work: reading, summarizing, calling tools, drafting, and updating records.
However, the signal to watch is whether those actions—including which tools the system reaches for—are logical for the task at hand. If a support assistant asked to summarize a complaint starts pulling unrelated account data, calling payroll or billing APIs, or preparing an outbound message, that is a breach of task scope and should be flagged immediately. It is a clear sign that the agent has been compromised, and every second it runs uninspected widens the blast radius. When those tools happen to be credentials, tokens, or production keys, the consequences are immediate, far-reaching, and potentially irreversible.
map every AI action back to the originating request and flag anything that falls outside the scope of the given task. Automatically, not on review.
- Data re-routing
Another angle to the point about contextual behavior we’ve been discussing: When an AI system is involved, data exfiltration can be intelligently made to look entirely normal by using generated links, summaries, email drafts, support replies, document text, API parameters, or attachments.
But if an AI assistant reads private customer records and embeds account details into a generated message or URL, the channel may look legitimate while the content is not, easily bypassing controls not specifically designed to catch it.
runtime controls that inspect what the system produces and where it sends it, not just where the data is stored and who has access.
- Suspicious memory writes
Persistent memory makes runtime risk last beyond a single session. A bad instruction, poisoned summary, or false preference can be stored and quietly influence future behavior.
The signal to watch is memory being updated after the agent has processed untrusted material such as uploaded files, inbound emails, support tickets, web pages, or chat messages. If a supplier-risk assistant reads a vendor document and saves a new preference that changes how future reviews are routed, there may be no damage in that session, but there will be damage in every session that follows.
evidence that memory writes are logged, reviewable, and monitored for changes made after the system processes untrusted content
Not sure which of these risks your current architecture is blind to?
Run the thirty-day audit below before you start rebuilding. It will tell you exactly where your program cannot see, who needs to be involved, and what to fix first:
30-day TPRM architecture check
This is not a solo exercise. The AI third-party risk gaps this blog describes are almost always cross-functional: security instruments, GRC interprets and documents, procurement acts at renewal, and legal flags jurisdictional exposure. The thirty days are about getting those functions aligned around a shared picture of where your current architecture cannot see.
Week 1: Convene and scope
Who: Security, GRC, Procurement, Legal
Action items:
- Convene a single cross-functional session
- Ask one question: for your highest-criticality AI-enabled vendor relationships, do you have dependency maps, runtime logs, and exit assessments you could produce on request today?
- Document every gap that surfaces
- Assign a named owner to each gap before the session closes
Desired output: Prioritized gap list with named owners
Week 2: Dependency mapping sprint
Who: Security, GRC
Action items:
- Identify your top ten AI vendor relationships by criticality
- For each vendor, document the model provider, cloud region, API dependencies, and subprocessors
- Flag any workflows that share the same underlying layer
- Enter findings into a shared register
Desired output: Concentration risk register. This should be a living document, not a one-and-done
Week 3: Runtime visibility audit
Who: Security (lead), GRC (review)
Action items:
- Assess what logging and monitoring currently exist for AI agent behavior across your environment
- Classify each gap as a tooling gap, configuration gap, or process gap
- Route tooling gaps into your next budget cycle
- Assign a remediation owner and timeline to every configuration and process gap before the week closes
- GRC reviews findings and determines what documentation and logging standards need to follow from each gap
Desired output: Runtime visibility gap report with owners and timelines
Week 4: Exit and evidence review
Who: Procurement, GRC
Action items:
- Identify your three most embedded AI vendors with upcoming renewal windows
- Run an exit feasibility assessment for each one
- Compile what evidence currently exists to demonstrate governance over your AI vendor relationships
- Don’t forget to document what evidence you cannot produce so that you have your build priority list for the next audit cycle
Desired output: Exit assessments and evidence inventory
How to build a TPRM architecture to mitigate AI risk
The six risks covered in this blog represent gaps in your TPRM architecture. A program built on periodic reviews, questionnaire-based diligence, and contract-level oversight made sense once, but it lacks a structural mechanism to detect today’s risks, such as stacked dependencies, runtime control failures, or regulatory access shocks.
A TPRM architecture that can catch these risks, on the other hand, has three structural requirements that traditional programs lack: 1) continuous discovery over scheduled intake, 2) runtime visibility over point-in-time assessment, and 3) evidence-led closure over questionnaire completion and mere retrospective evidence gathering. Here’s how these three structural differences play out in practice on a platform like Sprinto.
On the three dependency risks
- Sprinto discovers vendors as they enter your environment, not when someone remembers (or finds the time) to add them
- Sprinto maps dependency chains behind the contract, not just the application name on it
- Sprinto documents, flags, and validates concentration exposure, so shared underlying layers are visible and defensible
- Sprinto assesses exit feasibility, selection rationale, and mitigation plans before renewal, not after
On the three runtime signals
- Sprinto recalculates vendor exposure from live signals, not last quarter’s snapshot
- Sprinto detects and logs shadow AI adoption automatically
- Sprinto tracks runtime control dependencies—configurations, integrations, usage patterns—continuously
- When something shifts, Sprinto triggers the right review, assigns owners, and follows up to verified completion
Modern TPRM needs a closed loop: dependency chains mapped, runtime signals monitored, risk recalculated as things change, and evidence retained so your oversight is defensible when it matters. TPRM teams rearchitecting for AI vendor risk and AI third-party risk have a clear direction: With zero-day exploit potential having become an everyday reality, the new architecture needs to take your TPRM program from one that reviews vendors to one that continuously validates exposure.
FAQs
Start with your highest-criticality AI-enabled workflows and map backward. For each one, ask: what vendor powers this, what does that vendor depend on, and what happens if access disappears overnight? That dependency mapping exercise alone will surface your most urgent gaps without requiring a full program overhaul. Prioritize the workflows where a disruption would be immediate and visible. Think customer-facing processes, automated decisioning, and anything that touches sensitive data. Fix the architecture there first, then expand.
In most organizations today, nobody owns it, which is part of the problem. Procurement owns the contract. GRC owns the assessment. Security owns the tooling. But runtime behavior sits in the gap between all three. The practical answer is that security needs to instrument it, GRC needs to interpret it and retain the evidence, and procurement needs to factor it into renewal decisions. If you are waiting for one team to own it entirely, you will wait a long time. Define the handoffs instead.
Auditors and regulators are increasingly asking not just whether you assessed a vendor, but whether you maintained ongoing visibility. The evidence that answers that question includes: logged tool call histories for AI agents, memory write audit trails, dependency maps that show the layers beneath your contracted vendors, documented exit assessments at renewal, and records showing that concentration risk was identified, reviewed, and either mitigated or formally accepted. If you cannot produce these on request, your governance exists on paper but not in practice.
Start by asking every AI vendor in your stack which model provider, cloud region, and API dependencies underpin their product. Most will tell you if you ask directly. Then map the answers across your vendor list and look for patterns. If three tools all depend on the same underlying model provider or cloud region, you have concentration risk regardless of how many different vendor contracts you signed. The goal is a dependency map that shows the real architecture beneath your vendor relationships, not just the names on your contracts.
At every renewal, without exception. Exit feasibility changes as integrations deepen, workflows get rebuilt around vendor-specific logic, and user habits form. A vendor that was easy to replace eighteen months ago may be structurally embedded today. The reassessment does not need to be lengthy. It needs to answer one question honestly: if we had to leave this vendor in 90 days, what would break, and what would it cost to fix? If the answer is uncomfortable, that is information your renewal decision needs to include.
The most effective framing is not technical; it is operational. Start by explaining how traditional vendor risk has a natural review cadence: assess at onboarding, reassess annually, flag exceptions as they arise. The cost of that model is predictable and has been absorbed into most GRC budgets for years.
Then bring in the contrast. Explain how AI vendor risk does not have a natural resting state. The exposure changes between reviews as models update, integrations deepen, and agents are granted broader access. That means monitoring has to be continuous, not periodic, and continuous monitoring requires tooling, interpretation, and documented evidence that periodic reviews never needed to produce.
– For budget conversations, the concrete ask is threefold: tooling for runtime visibility that did not previously exist in your stack; GRC capacity to interpret signals and retain audit-ready evidence; and faster review cycles that consume more hours with the same headcount.
– For boards and senior leadership, the frame that lands is liability and defensibility. If an AI agent causes a data incident and your program has no runtime monitoring evidence, you cannot demonstrate that you were governing for the risk. That gap is increasingly what regulators and auditors are looking for.
– For procurement stakeholders, the frame is renewal leverage: without exit assessments and dependency mapping, you are negotiating renewals blind.
Author
Raynah
Raynah is a content strategist at Sprinto, where she crafts stories that simplify compliance for modern businesses. Over the past two years, she’s worked across formats and functions to make security and compliance feel a little less complicated and a little more business-aligned.Go beyond the surface and uncover the governance, risk, and compliance insights that actually matter.


Win digital goodies for boardroom success


Explore more








research & insights curated to help you earn a seat at the table.

